Algoritmo KNN
El algoritmo KNN es una técnica de aprendizaje automático que clasifica las clases a las que pertenecen los puntos de datos más cercanos.

El algoritmo KNN es una técnica de aprendizaje automático que clasifica las clases a las que pertenecen los puntos de datos más cercanos.
En otras palabras, el algoritmo KNN clasifica según la mayoría de los votos de sus ‘vecinos’ más cercanos. Con ‘vecinos’ nos referimos a los puntos de datos más cercanos del punto a clasificar, teniendo como límite un rango ya establecido.
Así pues, el algoritmo KNN (K-Nearest Neighbors) es un método de aprendizaje supervisado utilizado para resolver problemas de clasificación y regresión.
Características del algoritmo KNN
El algoritmo KNN tiene características propias que lo hacen útil según que aplicaciones. En este sentido, este algoritmo pertenece al denominado grupo de los ‘lazy’, lo que traducido al español sería ‘perezoso’. Debido a ello, el algoritmo KNN entre otros, posee una mecánica muy simple y no necesita una fase de entrenamiento específica.
Este algoritmo también destaca por ser no paramétrico, lo que se traduce en que no realiza una suposición de la distribución de los datos. En cualquier caso, es una desventaja, ya que tener una distribución de los datos ayuda a comprender mejor el dataset que se está trabajando.
Esto hace que sea un algoritmo fácil de entender y de implementar, y además, muy efectivo en espacios con alta densidad de datos.
Funcionamiento del KNN
A continuación, se va a explicar el funcionamiento del algoritmo KNN.
En primer lugar, etiquetamos las clases de un conjunto de datos y construimos un modelo que prediga las nuevas entradas al dataset.
En segundo lugar, cuando llega el momento en el que se presenta una nueva muestra, el algoritmo KNN busca los ‘k’ puntos de datos más cercanos en el espacio de características para, luego, determinar si pertenece en una clase u a otra. Gráficamente, sería tal que así:
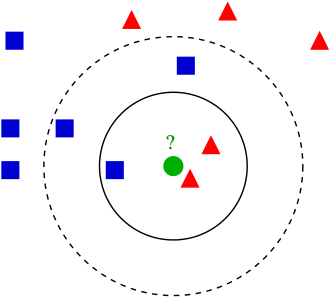
El funcionamiento del KNN determina primero un rango en forma de círculo y dentro de este, se estudian los datos dentro de este para mediante ‘votos’ y mayoría simple, determinar la clase de un nuevo dato o punto entrante a ese rango.
Ejemplos de aplicación del KNN
El algoritmo KNN se utiliza en un sector de aplicaciones delimitado, siendo su espacio de acción el siguiente:
- Recomendación de productos.
- Identificar tendencias.
- Predicción en entornos de ciencias sociales.
En lo que respecta a la recomendación de productos e identificación de tendencias, utiliza las mayorías simples para tomar decisiones y predecir, lo cual, es medianamente efectivo en grandes volúmenes de datos sin muchas clases.
Por último, en la predicción de entornos de ciencias sociales, su fuerte está en que para estudiar dinámicas pertenecientes a alguna ciencia social las muestras de estudio suelen ser grandes y las clases si son muy numerosas, se emplean intervalos para acortarlas. Un ejemplo sería con la edad, la cual en lugar de crear 100 clases 1 por cada año posible de un sujeto, se suelen utilizar intervalos del estilo: 0-5, 6-18, 19-35, 36-50, 51-75, 76-100, entre otros posibles.
Autores
Publicado por Jonathan Llamas el 10 noviembre 2023.
Revisado por última vez el 10 noviembre 2023.
Cómo citar este artículo
Llamas, J. (2023). Algoritmo KNN. Economipedia. https://economipedia.com/definiciones/tecnologia/algoritmo-knn.html
Sobre Economipedia
Este artículo forma parte de la enciclopedia de Economipedia, una plataforma de educación financiera que ayuda a millones de personas a entender la economía, aprender a invertir y mejorar sus finanzas personales. Fundada en 2012 por Andrés Sevilla Arias y desarrollada por más de 50 economistas y asesores financieros.
Todavía no hay comentarios
Hay 2 tipos de personas: las que leen y se van…y las que dejan huella 👇




