Distribución normal: Qué es, cómo se calcula y ejemplos
La distribución normal es un patrón estadístico para datos agrupados alrededor de un promedio, y esencial en análisis y predicciones precisas


- Es un modelo teórico que aproxima el comportamiento de una variable aleatoria a una situación ideal.
- Utiliza la media y la desviación típica como parámetros clave.
¿Qué es la distribución normal?
Es un modelo teórico capaz de aproximar satisfactoriamente el valor de una variable aleatoria a una situación ideal.
La distribución normal es una forma de describir cómo se comportan ciertos datos.
La distribución normal explicada fácil
Imagina que tienes un conjunto de datos, como los resultados de un examen o las rentabilidades de las acciones en el mercado. Ésta nos ayuda a entenderlos usando dos números claves: la media y la desviación típica.
La media es como el promedio de los datos, mientras que la desviación típica nos dice qué tan dispersos están los datos alrededor de este promedio.
Hay dos tipos de datos que podemos analizar gracias a ella: Uno es el tipo continuo, que puede tomar cualquier valor. Piensa en cosas como las valoraciones de un examen o del coeficiente de inteligencia. El otro tipo es el discreto, que sólo pueden ser números enteros, como por ejemplo el número de estudiantes de una universidad.
La distribución normal es la base de otras distribuciones como la t de Student, la ji-cuadrada, y la F de Fisher entre otras.
Fórmula de la distribución normal
Dada una variable aleatoria X, decimos que la frecuencia de sus observaciones puede aproximarse satisfactoriamente a una distribución normal tal que:
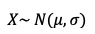
Donde los parámetros de la distribución son la media o valor central y la desviación típica:

En otras palabras, estamos diciendo que la frecuencia de una variable aleatoria X puede representarse mediante una distribución normal.
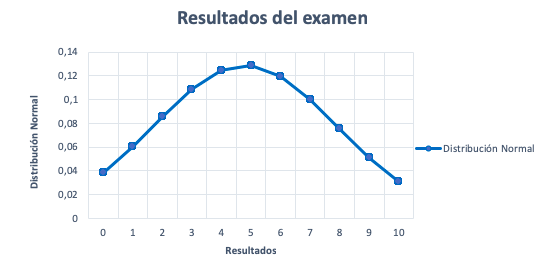
Representación gráfica de la distribución normal
Función de densidad de probabilidad de una variable aleatoria que sigue una distribución normal.
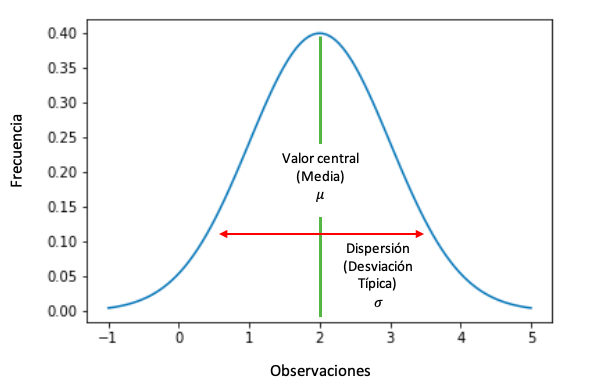
Propiedades
- Es simétrica. El valor de la media, la mediana y la moda coinciden. Matemáticamente,
Media = Mediana = Moda
- Distribución unimodal. Los valores que son más frecuentes o que tienen más probabilidad de aparecer están alrededor de la media. En otras palabras, cuando nos alejamos de la media, la probabilidad de aparición de los valores y su frecuencia descienden.
¿Qué necesitamos para representar una distribución normal?
- Una variable aleatoria.
- Calcular la media.
- Calcular la desviación típica.
- Decidir la función que queremos representar: función de densidad de probabilidad o función de distribución.
Ejemplo teórico
Suponemos que queremos saber si los resultados de un examen pueden aproximarse satisfactoriamente a una distribución normal.
Sabemos que en este examen participan 476 estudiantes y que los resultados podrán oscilar entre 0 y 10. Calculamos la media y la desviación típica a partir de las observaciones (resultados del examen).
Entonces, definimos la variable aleatoria X como los resultados del examen que depende de cada resultado individual. Matemáticamente,
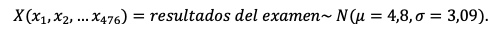
El resultado de cada estudiante se anota en una tabla. De esta forma, obtendremos una visión global de los resultados y de su frecuencia.
| Resultados | Frecuencia |
| 0 | 20 |
| 1 | 31 |
| 2 | 44 |
| 3 | 56 |
| 4 | 64 |
| 5 | 66 |
| 6 | 62 |
| 7 | 51 |
| 8 | 39 |
| 9 | 26 |
| 10 | 16 |
| TOTAL | 475 |
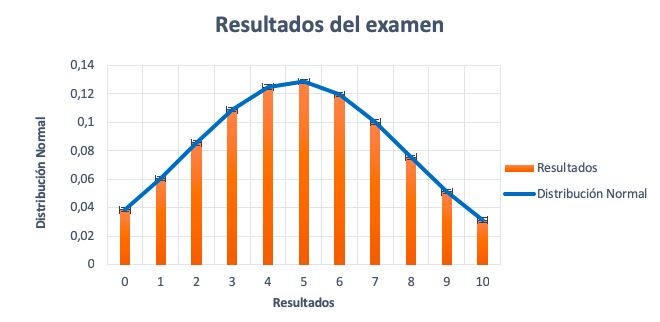
Una vez hecha la tabla, representamos los resultados del examen y las frecuencias. Si el gráfico se parece a la imagen anterior y cumple con las propiedades, entonces, la variable resultados del examen puede aproximarse satisfactoriamente a una distribución normal de media 4,86 y desviación típica de 2,56.
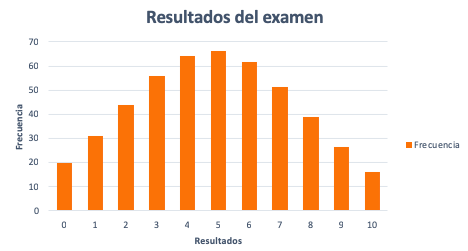
¿Los resultados del examen pueden aproximarse a una distribución normal?
Razones para considerar dicho caso son:
- Distribución simétrica. Es decir, existe el mismo número de observaciones tanto a la derecha como a la izquierda del valor central. También, que la media, la mediana y la moda tienen el mismo valor.
Media = Mediana = Moda = 5
- Las observaciones con más frecuencia o probabilidad están alrededor del valor central. En otras palabras, las observaciones con menos frecuencia o probabilidad se encuentran lejos del valor central.
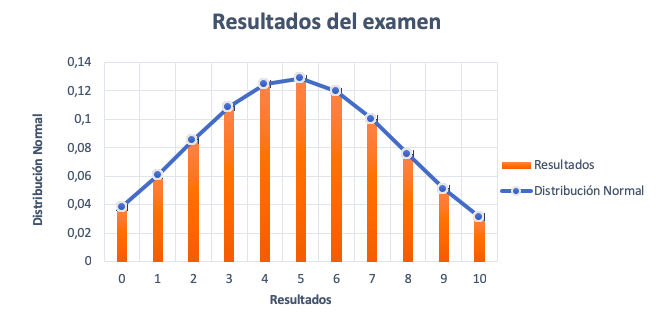
La distribución normal describe la variable aleatoria mediante una aproximación que produce errores estándar (las barras encima de cada columna). Estos errores son la diferencia entre las observaciones reales (resultados) y la función de densidad.
Preguntas frecuentes
Autores
Publicado por Paula Rodó el 10 noviembre 2019.
Revisado por última vez el 14 mayo 2025.
Cómo citar este artículo
Rodó, P. (2019). Distribución normal: Qué es, cómo se calcula y ejemplos. Economipedia. https://economipedia.com/definiciones/distribucion-normal.html
Sobre Economipedia
Este artículo forma parte de la enciclopedia de Economipedia, una plataforma de educación financiera que ayuda a millones de personas a entender la economía, aprender a invertir y mejorar sus finanzas personales. Fundada en 2012 por Andrés Sevilla Arias y desarrollada por más de 50 economistas y asesores financieros.
Comentarios
Hola, como calcularon los valores de la tabla de frecuencia??
27 Comentarios
Buenas, para poder realizar una distribución normal, es necesario tener un rango de datos?
Muy buena explicación, logré entender de que se trataba el tema, muy buena explicación 👏🏽👏🏽👏🏽👏🏽
Cuando el valor de p me sale <.0001. Significa qué la prueba de distribucion no es normal, sin embargo en la prueba de normalidad descriptiva me sale como dato que la prueba es tiene distribución normal.
Si llega a ser no paramétrica tiene algún problema?
Resultados Frecuencia
0 20
1 31
2 44
3 56
4 64
5 66
6 62
7 51
8 39
9 26
10 16
TOTAL 475
Hola, estoy aprendiendo sobre estadística y tengo una duda. He replicado el estudio propuesto como ejemplo y los datos no me coinciden: La sumatoria total de los estudiantes me sale 475 y la desviación estándar me sale 2.556147994. Indicar si estos datos son correctos
475
Gracias por avisarnos Daniel.
Así es, ya lo hemos modificado. Estos serían los cálculos:
μ = (0.042×0+0.065×1+0.093×2+0.118×3+0.135×4+0.139×5+0.131×6+0.107×7+0.082×8+0.055×9+0.034×10) / (0.042+0.065+0.093+0.118+0.135+0.139+0.131+0.107+0.082+0.055+0.034) = 4.86113886
σ = √( (0.042×(0-4.86113886)²+0.065×(1-4.86113886)²+0.093×(2-4.86113886)²+0.118×(3-4.86113886)²+0.135×(4-4.86113886)²+0.139×(5-4.86113886)²+0.131×(6-4.86113886)²+0.107×(7-4.86113886)²+0.082×(8-4.86113886)²+0.055×(9-4.86113886)²+0.034×(10-4.86113886)²) / (0.042+0.065+0.093+0.118+0.135+0.139+0.131+0.107+0.082+0.055+0.034) ) = 2.55639651
Gracias!
¿A partir de cuántas observaciones puedo utilizar la distribución normal?
Por ejemplo, en otro artículo mencionan que "A partir de 30 observaciones, la distribución t se parece mucho a la distribución normal y, por tanto, utilizaremos la distribución normal."
Tengo 48 observaciones para realizar un pronóstico de ventas con suavización exponencial doble, y me gustaría saber cuál debe ser el tamaño de mis datos para asumir que se distribuyen normalmente. Mi profesor que mínimo son 28, pero no encuentro literatura que me lo indique explícitamente.
Les agradezco.
Hola Juan.
Gracias por tu comentario.
El objetivo por el cual se prefiere trabajar con la distribución normal que con otras distribuciones es por sus propiedades estadísticas.
Para saber si tus datos siguen una distribución normal podrías hacer un prueba de Jarque-Bera y determinar si la asimetría y la curtosis de tus datos son normales.
Es tan importante el número de datos del conjunto como su distribución para aproximarla a la distribución normal.
La distribución t-Student es una distribución continua pensada para estimar la media de una población normalmente distribuida con una muestra pequeña, entonces, a partir de 30 observaciones ya se considera una distribución normal. Si no encuentras literatura al respecto, puedes demostrarlo simulando unos datos e incrementando los grados de libertad hasta llegar a 30 y ver que encaja con una distribución normal ya que los grados de libertad dependen del tamaño de la muestra.
Un saludo.
muy buena explicación, solo que la suma de las frecuencias en la tabla de distribución no son 476, si no 475. Tendrían que verificas si son 476 o 476.
Hola,
Gracias por la observación. La tabla ya tiene la cifra correcta, 475, al parecer fue corregida luego que usted dejó su comentario, pero antes de esta respuesta.
Saludos
Holaa, me hacen una pregunta en mi exámen final, que no logro responder, es que beneficio tiene que una distribución normal tenga una gráfica simétrica respecto del eje vertical? Sería de gran ayuda una respuesta. Gracias.
Hola Evelyn,
Quizás este artículo pueda ayudarte ↓
https://economipedia.com/definiciones/curtosis.html
Un saludo y muchas gracias por comentar.
Las variables discretas... ¿pueden tener también una distribución normal?
Hola Carlos,
Sí, les variables discretas también pueden tener una distribución normal.
La diferencia entre una variable discreta y una variable continua es que la variable continua tiene infinitas posibilidades entre observaciones y la variable discreta no existe nada entre observaciones. Entonces, si representas un conjunto de datos discreto y ves que los valores centrales aparecen con más frecuencia que los valores extremos, verás como va tomando la forma de una distribución normal. Puedes calcular la función de densidad de probabilidad (pdf) de esos valores y obtendrás la probabilidad (según la distribución normal) para cada valor de tu conjunto de datos. Cuántos más datos tenga tu conjunto de datos, más se parecerá a la distribución normal porque estás añadiendo continuidad a la serie.
Un saludo.
Me llama la atención que dicen que necesitamos una variable continua, pero calificaciones toma solo valores enteros. Me queda esa duda
Hola Jose,
El artículo está enfocado hacia las variables aleatorias continuas dado que son las más utilizadas en las finanzas. En el ejemplo se utiliza una variable discreta para simplificar. Si lo prefiere, puede añadir decimales a la variable resultados del examen para que tenga la condición de continuidad. Gracias por su comentario, modificaremos el artículo para facilitar la comprensión.
Un saludo.
gracias , me ayudado mucho con mi materia de estadística descriptiva muy buenas aportaciones
me gustaria saber cuando fue la fecha de la publicacion para mi trabajo de investigacion
Economipedia es la carrera de ADE o Economía, condensada de forma absolutamente fácil. Se nota que los autores vienen de estas carreras, vamos, de diez!
Muchas gracias Luz;
La verdad es que, pese a que contamos con un equipo multidisciplinar, casi todos los autores en Economipedia provienen de los grados de Economía, derecho y ADE.
Estamos muy contentos de que te guste la página, así como que te sirva de ayuda.
Un abrazo de parte del equipo de Economipedia.
muy buena la explicacion gracias !!
Una aportación concreta y precisa, gracias
hola
Hola Nicole,
¿En qué podemos ayudarte?
Saludos y gracias por leernos.





Hola, como calcularon los valores de la tabla de frecuencia??