Propiedades de los estimadores

Las propiedades de los estimadores son las cualidades que pueden tener estos y que sirven para escoger aquellos que son más capaces de arrojar buenos resultados.
Por empezar definiendo el concepto de estimador, diremos que dada una muestra aleatoria cualquiera {x1,x2,x3, … ,xn} un estimador representa a una población que depende de φ un parámetro que desconocemos.
Este parámetro al que nosotros denotamos con la letra griega fi (φ), puede ser, por ejemplo, la media de una variable aleatoria cualquiera.
Matemáticamente, un estimador Q de un parámetro depende de las observaciones aleatorias de la muestra {x1,x2,x3, … ,xn} y de una función conocida (h) de la muestra. El estimador (Q) será una variable aleatoria porque depende de la muestra que contiene variables aleatorias.
Q = h{x1,x2,x3, … ,xn}
Insesgadez de un estimador
Un estimador Q de φ es un estimador insesgado si E(Q)= φ para todos los valores posibles de φ .Definimos E(Q) como el valor esperado o esperanza del estimador Q.
En el caso de presencia de estimadores sesgados, este sesgo se representaría como:
Sesgo (Q) = E(Q) – φ
Podemos ver que el sesgo es la diferencia entre el valor esperado del estimador, E(Q), y el verdadero valor del parámetro poblacional, φ.
Eficiencia de un estimador
Si Q1 y Q2 son dos estimadores insesgados de φ , será eficiente su relación con Q2 cuando Var(Q1) ≤ Var(Q2) para cualquier valor de φ siempre que la muestra estadística de φ sea estrictamente mayor a 1, n>1. Siendo Var, la varianza y n, el tamaño de la muestra.
Dicho de forma intuitiva, suponiendo que tenemos dos estimadores con la propiedad de insesgadez, podemos decir que uno (Q1) es más eficiente que otro (Q2) si la variabilidad de los resultados de uno (Q1) es menor que la del otro (Q2) . Es lógico pensar que una cosa que varía más que otra es menos ‘precisa’.
Por tanto, sólo podemos usar este criterio de selección de estimadores cuando son insesgados. En el enunciado anterior cuando estamos definiendo la eficiencia ya suponemos que los estimadores tienen que ser insesgados.
Para comparar estimadores que no son necesariamente insesgados, esto es, que puede existir sesgo, se recomienda calcular el Error Cuadrático Medio (ECM) de los estimadores.
Si Q es un estimador de φ , entonces el ECM de Q se define como:
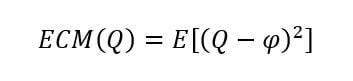
El Error Cuadrático Medio (ECM) calcula la distancia promedio que existe entre el valor esperado del estimador muestral Q y el estimador poblacional. La forma cuadrática del ECM se debe a que los errores pueden ser por defecto, negativos, o por exceso, positivos, respecto al valor esperado. De este modo, ECM siempre computará valores positivos.
ECM depende de la varianza y del sesgo (en el caso que lo hubiera) permitiéndonos comparar dos estimadores cuando uno o ambos son sesgados. Aquel cuyo ECM sea mayor se entenderá que es menos preciso (tiene más error) y, por tanto, menos eficiente.
Consistencia de un estimador
La consistencia es una propiedad asintótica. Esta propiedad se parece a la propiedad de eficiencia con la diferencia de que la consistencia mide la distancia probable entre el valor del estimador y el valor verdadero del parámetro poblacional a medida que el tamaño de la muestra aumenta indefinidamente. Este aumento indefinido del tamaño de la muestra es la base de la propiedad asintótica.
Existe una dimensión de muestra mínima para llevar a cabo el análisis asintótico (comprobar la consistencia del estimador a medida que aumenta la muestra). Aproximaciones de muestras grandes funcionan correctamente para muestras de alrededor de 20 observaciones, (n = 20). En otras palabras, queremos ver como se comporta el estimador cuando aumentamos la muestra, pero este aumento tiende a infinito. Dado esto, hacemos una aproximación y a partir de 20 observaciones en una muestra (n ≥ 20), es apropiado el análisis asintótico.
Matemáticamente, definimos Q1n como un estimador de φ de una muestra aleatoria cualquiera {x1,x2,x3, … ,xn} de tamaño (n). Entonces, podemos decir que Qn es un estimador consistente de φ si:
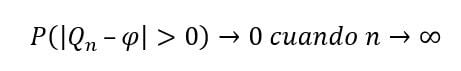
Esto nos dice que las diferencias entre el estimador y su valor poblacional, |Qn – φ|, tienen que ser mayores que cero. Por esto lo expresamos en valor absoluto. La probabilidad de esta diferencia tiende a 0 (se hace cada vez más pequeña) cuando el tamaño de la muestra (n) tiende a infinito (se hace cada vez más grande).
Dicho de otro modo, cada vez es menos probable que Qn se aleje mucho de φ cuando aumenta el tamaño de la muestra.
Autores
Publicado por Paula Rodó el 12 mayo 2019.
Revisado por última vez el 24 noviembre 2022.
Cómo citar este artículo
Rodó, P. (2019). Propiedades de los estimadores. Economipedia. https://economipedia.com/definiciones/propiedades-de-los-estimadores.html
Sobre Economipedia
Este artículo forma parte de la enciclopedia de Economipedia, una plataforma de educación financiera que ayuda a millones de personas a entender la economía, aprender a invertir y mejorar sus finanzas personales. Fundada en 2012 por Andrés Sevilla Arias y desarrollada por más de 50 economistas y asesores financieros.
Todavía no hay comentarios
Hay 2 tipos de personas: las que leen y se van…y las que dejan huella 👇




