Un intervalo de confianza es una técnica de estimación utilizada en inferencia estadística que permite acotar un par o varios pares de valores, dentro de los cuales se encontrará la estimación puntual buscada (con una determinada probabilidad).
Un intervalo de confianza nos va a permitir calcular dos valores alrededor de una media muestral (uno superior y otro inferior). Estos valores van a acotar un rango dentro del cual, con una determinada probabilidad, se va a localizar el parámetro poblacional.
Intervalo de confianza = media +- margen de error
Conocer el verdadero poblacional, por lo general, suele ser algo muy complicado. Pensemos en una población de 4 millones de personas. ¿Podríamos saber el gasto medio en consumo por hogar de esa población? En principio sí. Simplemente tendríamos que hacer una encuesta entre todos los hogares y calcular la media. Sin embargo, seguir ese proceso sería tremendamente laborioso y complicaría bastante el estudio.
Ante situaciones así, se hace más factible seleccionar una muestra estadística. Por ejemplo, 500 personas. Y sobre dicha muestra, calcular la media. Aunque seguiríamos sin saber el verdadero valor poblacional, podríamos suponer que este se va a situar cerca del valor muestral. A esa media le sumamos el margen de error y tenemos un valor del intervalo de confianza. Por otro lado, le restamos a la media ese margen de error y tendremos otro valor. Entre esos dos valores estará la media poblacional.
En conclusión, el intervalo de confianza no sirve para dar una estimación puntual del parámetro poblacional, si nos va a servir para hacernos una idea aproximada de cuál podría ser el verdadero de este. Nos permite acotar entre dos valores en dónde se encontrará la media de la población.
Factores de los que depende un intervalo de confianza
El cálculo de un intervalo de confianza depende principalmente de los siguientes factores:
- Tamaño de la muestra seleccionada: Dependiendo de la cantidad de datos que se hayan utilizado para calcular el valor muestral, este se acercará más o menos al verdadero parámetro poblacional.
- Nivel de confianza: Nos va a informar en qué porcentaje de casos nuestra estimación acierta. Los niveles habituales son el 95% y el 99%.
- Margen de error de nuestra estimación: Este se denomina como alfa y nos informa de la probabilidad que existe de que el valor poblacional esté fuera de nuestro intervalo.
- Lo estimado en la muestra (media, varianza, diferencia de medias…): De esto va a depender el estadístico pivote para el cálculo del intervalo.
Ejemplo de intervalo de confianza para la media, asumiendo normalidad y conocida la desviación típica
El estadístico pivote utilizado para el cálculo sería el siguiente:
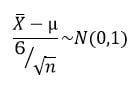

El intervalo resultante sería el siguiente:
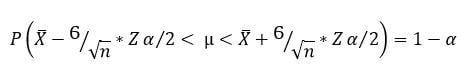
Vemos como en el intervalo a la izquierda y derecha de la desigualdad tenemos la cota inferior y superior respectivamente. Por tanto la expresión nos dice, que la probabilidad de que la media poblacional se sitúe entre esos valores es de 1-alfa (nivel de confianza).
Veamos mejor lo anterior con un ejercicio resuelto a modo de ejemplo.
Se desea estimar la media del tiempo que un corredor emplea para completar una maratón. Para ello se han cronometrado 10 maratones y se ha obtenido una media de 4 horas con una desviación típica de 33 minutos (0,55 horas). Se desea obtener un intervalo al 95% de confianza.

Para obtener el intervalo, no tendríamos más que sustituir los datos en la fórmula del intervalo.
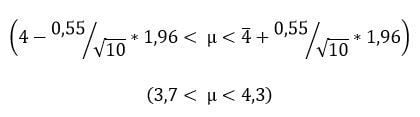

El intervalo de confianza, sería la parte de la distribución que queda sombreada en azul. Los 2 valores acotados por este serían los correspondientes a las 2 líneas de color rojo. La línea central que parte la distribución en 2 sería el verdadero valor poblacional.
Es importante resaltar que en este caso, dado que la función de densidad de la distribución N(0,1) nos da la probabilidad acumulada (desde la izquierda hasta el valor crítico), tenemos que encontrar el valor que nos deja a la izquierda 0,975% (este es 1,96).




