Generación de una muestra aleatoria con R
Aprende a generar una muestra aleatoria con R para tus análisis estadísticos. Descubre cómo obtener datos representativos para contrastar tus experimentos.

En el campo de las ciencias se realizan muchos experimentos que tienen que contrastarse mediante un test estadístico para ver si realmente el resultado obtenido es significativo y verosímil. Una vez comparado el estadístico con el valor crítico y anotada la conclusión, damos por sentado que hemos terminado.
La formación básica en inferencia estadística centra toda la atención en el contraste, pero si estamos dispuestos a profundizar más, veremos que la parte fundamental recae en la obtención y calidad de la muestra y la tipología de los datos.
Para obtener una muestra primero necesitamos tener una población. Existen técnicas complejas para determinar si una muestra es lo suficientemente representativa como para utilizarla en vez de utilizar la población. En los ensayos básicos tratamos la muestra como dada y no cuestionamos cómo se han obtenido los datos.
¿Y cómo obtenemos una muestra? ¿Salimos a la calle y preguntamos a todas las personas que encontremos? Y si hacemos una encuesta, ¿cómo hacemos un análisis estadístico de las respuestas de la gente? Y basándome en la teoría económica, ¿cómo encuentro un modelo matemático que mejor se adapte a los datos? ¿Cómo? ¿Qué dices? ¿Qué si la relación entre mis datos no es lineal, no puedo utilizar el estimador de mínimos cuadrados? ¿Y encima tengo que imputar los datos si a la muestra le falta información o tiene errores? Madre mía qué complicado…
Efectivamente, sí, existe mundo más allá de los casos utópicos y generales que nos dan en la universidad y es difícil adaptarse a casos específicos con problemas como los descritos en el párrafo anterior. No hay que desesperarse pues todas las dudas que nos surgen están resueltas y existe solución.
No obstante, podemos prescindir de todos los problemas anteriores y crear nosotros mismos un conjunto de datos con las peculiaridades y medida que queramos: determinista o aleatorio, con vacíos o sin ellos, valores negativos o positivos, datos cualitativos o cuantitativos…
Con la ayuda del programa estadístico R podemos dejar ir nuestra imaginación y crear tantas muestras como queramos.
Objetivo
En este artículo nos centraremos en generar un muestreo aleatorio utilizando el programa R Studio y ahorrarnos perseguir a las personas por la calle o tener dolores de cabeza para la imputación de datos.
Definición
El muestreo aleatorio mediante computación consiste en generar la cantidad de datos que el analista quiere crear una vez conociendo la distribución que van a seguir dichos datos.
En otras palabras, utilizando programas estadísticos nos podemos olvidar de calcular las fórmulas a mano y sufrir por si nos equivocamos en algún paso. Solo necesitamos saber sobre qué disponemos y qué queremos.
Planteamiento
Antes de abrir el programa, tenemos que plantear el problema de manera inversa a la que estamos acostumbrados a plantear. Es decir, estamos habituados a encontrar un conjunto de datos y representarlos para ver qué distribución siguen. Para generar la muestra tendremos que hacer el proceso inverso.
El primer paso sería tener instalado el programa R, preferiblemente R Studio dado que el diseño es mejor y es mucho más visual. Aquí trabajaremos con R Studio.
- Abrimos R Studio.
- Abrimos un guion nuevo (New Script).
- Instalar la librería stats para poder tener funciones estadísticas y generación de números aleatorios.
- Función help(“dnorm”). Esta función nos permite encontrar una fórmula matemática concreta dentro de las librerías y nos da información sobre la utilidad, parámetros, resultados, referencias e incluso ejemplos en los casos más populares.
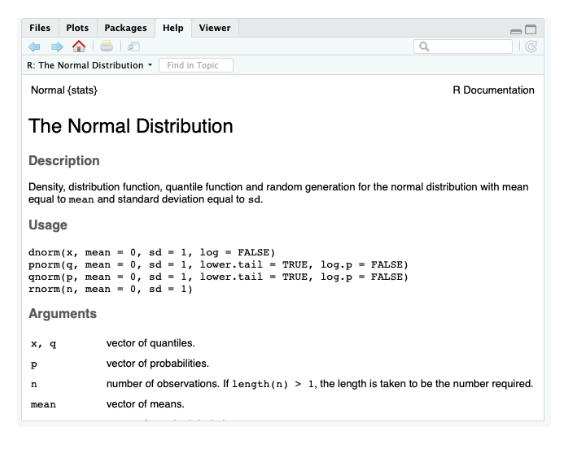
5. Para calcular una muestra aleatoria a partir de una distribución normal tenemos que conocer sus parámetros muestrales, es decir, su media y su desviación típica. Si estuviéramos generando una muestra mediante una t-Student nos bastaría solo con conocer los grados de libertad. El ejemplo que estamos haciendo se puede hacer con cualquier distribución siempre que la librería esté instalada en la computadora y se le asignen valores a los parámetros necesarios para calcular la función de densidad de la distribución.
A continuación mostramos algunas distribuciones con R:
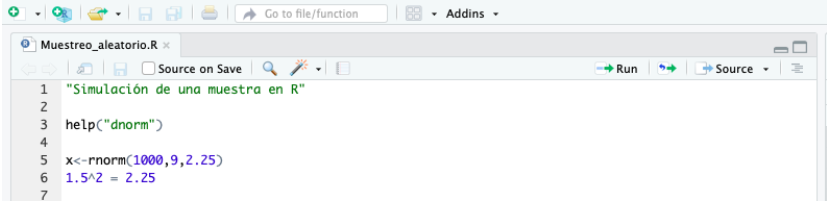
6. Simulamos una muestra donde la frecuencia de las observaciones puede aproximarse suficientemente a una distribución normal. Dado que estamos trabajando con una distribución normal, tenemos que definir su media y su varianza. Suponemos una media de 9 y varianza de 2,25. Asignamos a la variable X la generación de números aleatorios.
IMPORTANTE: R entiende los parámetros de la distribución normal como media y desviación típica, por tanto, si queremos tener una varianza de 2,25, tendremos que escribir 1,5 en R. Tal que 1,5^2 = 2,25.
7. Para obtener una muestra con números aleatorios que siguen una distribución normal, tenemos que utilizar la fórmula rnorm. Del inglés, r equivale a random que significa aleatorio y norm equivale a normal distribution, es decir, distribución normal. Esta información aparece en el lado inferior izquierdo de la pantalla cuando hacemos el comando de help(“dnorm”).
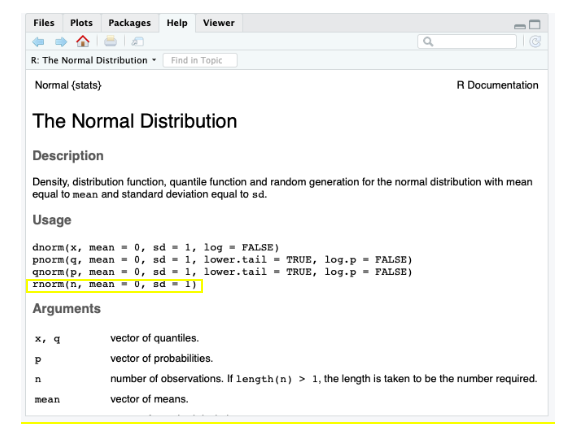
Por defecto R entiende que si no especificamos ni la media ni la varianza, este asignará un valor de 0 a la media y 1 a la varianza. En otras palabras, tratará la distribución como una distribución normal estándar.
8. Una vez calculada la muestra solo queda ver si lo hemos hecho bien. Es decir, que R nos muestre los valores de la variable X. Solo tenemos que poner x en el guion y aparecerán los datos. Podemos ver que los datos de la muestra aparecen alrededor del número 9 (media) con una ligera diferencia de 1,5% (desviación).
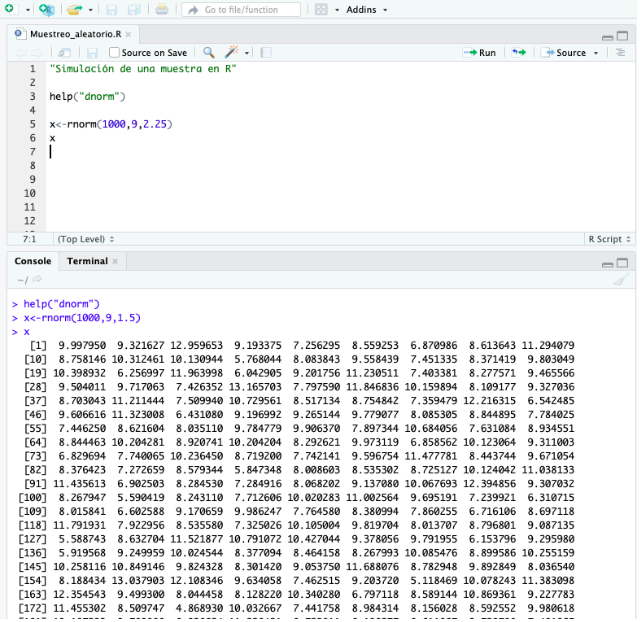
Los números de la izquierda entre corchetes [ ] significan la posición del número que tienen a su derecha. Es un método que utiliza R para poder tener una visión general del número de datos pertenecientes a cada fila.




