Red neuronal convolucional
Red neuronal convolucional
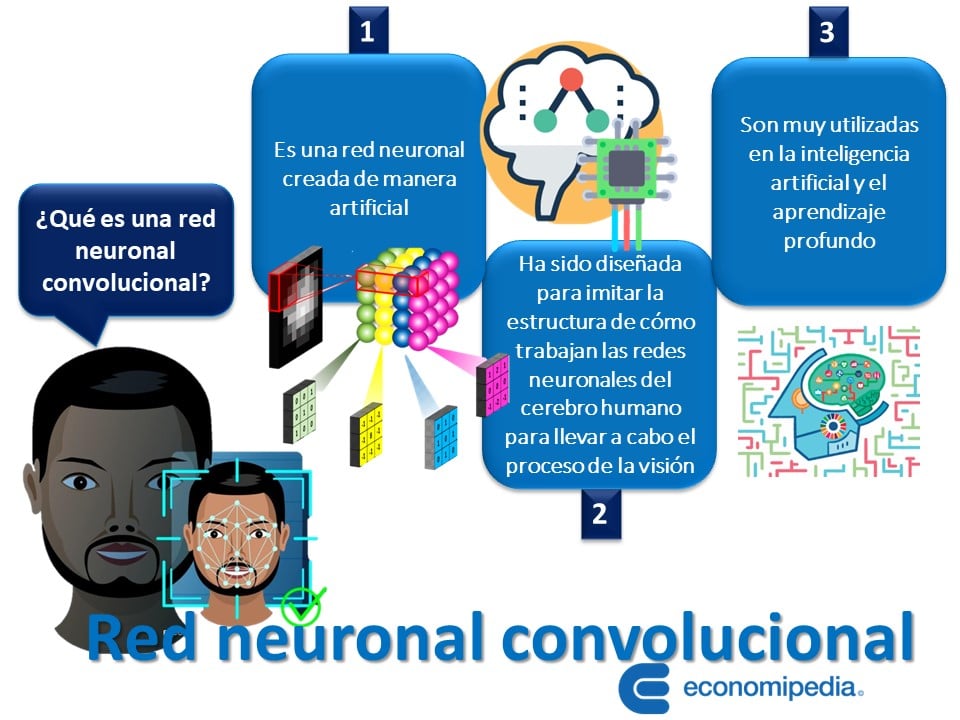
La red neuronal convolucional se puede definir como una red neuronal creada de manera artificial para que las computadoras puedan procesar imágenes.
Es decir, que la red neuronal convolucional ha sido diseñada para imitar la estructura de cómo trabajan las redes neuronales del cerebro humano para llevar a cabo el proceso de la visión. Son muy utilizadas en la inteligencia artificial y el aprendizaje profundo. Especialmente, en el campo del procesamiento de imágenes. También, son conocidas como CNN (Convolutional Neural Network).
Básicamente, las redes de neuronas convolucionales pueden distinguir por medio de una arquitectura de capas tres dimensiones. Estas dimensiones son el ancho, la altura y la profundidad. Además de las capas de color para distinguir el rojo, el verde y el azul. En otras palabras, son capaces de aprender a distinguir estas características por medio del cálculo de convoluciones en una serie de datos.
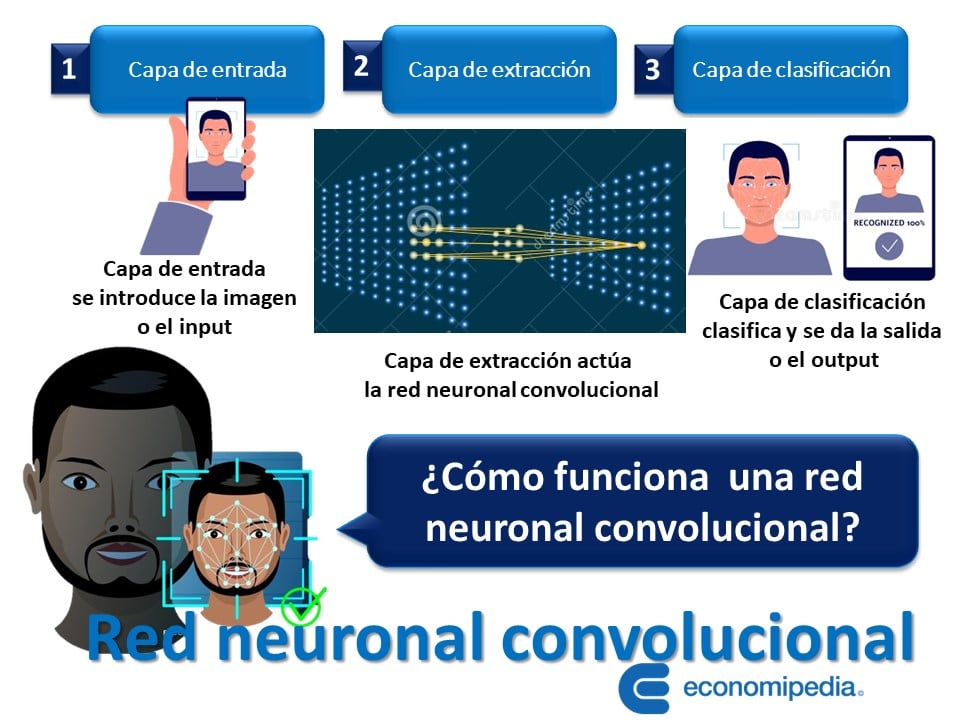
Efectivamente, una red neuronal convolucional necesita estructurarse por lo menos con tres tipos de capas. Primero una capa de entrada, luego una capa o varias de extracción de las características y una capa final de clasificación. Por esa razón, resultan muy útiles para aplicarlas en el procesamiento de la visión de las computadoras y para que puedan reconocer objetos.
Por otra parte, para que se pueda realizar este proceso, la computadora necesita emplear una serie de lentes que le sirven de filtros. De esa forma, es capaz de ver las diferentes características de las redes neuronales convolucionales. Las máquinas son capaces de pasar estos filtros o lentes sobre una imagen, la escanea, para finalmente definirla y clasificarla.
¿Qué es una red neuronal convolucional?
Cómo funciona la red neuronal convolucional
La estructura más básica de una red neuronal convolucional debe tener las siguientes capas para poder funcionar:
1. Capa de entrada
Para comenzar, la capa de entrada es la capa donde la red neuronal recibe todos los datos que provienen del exterior. Si la entrada es una imagen, tendrá las tres dimensiones de ancho, alto y profundidad. En la máquina serán los píxeles de la imagen, por ejemplo, los tres valores RGB de cada valor.
2. Capa de extracción de las características
Luego, viene una serie de capas que buscan encontrar información que resulte relevante, para que de manera progresiva se puedan ir generando características de un orden superior. Las capas de extracción de características se pueden clasificar en dos tipos:
a. Capa de convolución
En efecto, las capas de convolución se encargan de calcular esta función. Es decir, que en esta capa se analizan las imágenes obtenidas en el proceso de entrada. Detectando un conjunto de características, a la salida de esta capa ya se cuenta con un conjunto o un mapa de características que resultan determinantes.
b. Capa de pooling
Enseguida, la capa de pooling es la que reúne los resultados que se van obteniendo de todas las capas anteriores. Por eso, es una operación que se produce entre dos capas de convolución. En la entrada de la capa de pooling se recibe el mapa de características obtenido a la salida de la capa de convolución. Su tarea principal es reducir el tamaño de la imagen, pero conservando todas las características que resultan esenciales. Entre los métodos más usados encontramos:
- El max-pooling: Es el que calcula el máximo de los elementos. Por lo tanto, es el que conserva el máximo de los datos y luego crea una nueva matriz de salida. En la salida cada elemento corresponde al máximo de cada región analizada. Por ejemplo, si se tiene una matriz de entrada inicial de 4×4 y luego una ventana de filtro de 2×2 que se aplica a la entrada. La matriz de salida conserva los máximos de cada elemento.
- El average-pooling: Es el que calcula la media de los elementos. En este caso se debe conservar, en cada paso, el valor medio de la ventana utilizada como filtro.
La salida de la capa de pooling genera un nuevo mapa de salida, pero más pequeño o de manera comprimida.

Ejemplo del procesamiento del max-pooling
c. Capa de clasificación
Naturalmente, la capa de clasificación corresponde a la última etapa de salida de una red neuronal convolucional. Luego, que la máquina aprende a reconocer diversas características importantes de las capas anteriores, se encuentra en la capacidad de poder hacer la clasificación final.
Sin duda, la capa final de la estructura de la red neuronal emplea una capa de clasificación, para obtener la salida de la clasificación final. Esto se consigue con el uso de una red neuronal de muchas capas que usa funciones de activación como signo/ideas que le permiten hacer la clasificación.
¿Cómo funciona una red neuronal convolucional?
¿Cuál es la importancia de las redes neuronales convolucionales?
Las redes neuronales convolucionales son fundamentales. Porque, con su empleo, las computadoras pueden descubrir y aprender características clave en imágenes y series de datos temporales. Sus aplicaciones más importantes las encontramos en:
- Predicción y detección de enfermedades: Esto la máquina puede hacerlo al analizar imágenes médicas. Las redes convolucionales pueden examinar miles de informes anatómicos y patológicos para detectar de forma visual la presencia o ausencia de algunas enfermedades. Como puede ser la detección de células cancerígenas en el organismo.
- Reconocimiento de voz: Las máquinas logran realizar procesamiento de audios, al detectar algunas palabras clave. Las redes neuronales permiten que los dispositivos que poseen audio logren aprender y distinguir con precisión la o las palabras clave y hacen caso omiso de otra o de otras. Esto en distintos entornos. Como el reconocimiento en los celulares de asistentes como Siri, Alexa o Cortana.
- Detección de objetos: Las redes neuronales convolucionales permiten detectar ciertos objetos y señales, para luego tomar una decisión de salida. Esto tiene aplicación en la conducción autónoma de automóviles, por ejemplo.
- Reproducción de datos sintéticos: Con estas redes se puede producir aprendizaje profundo. Dado que, las máquinas pueden generar nuevas imágenes. Como puede ser el caso del reconocimiento facial en los diferentes dispositivos. O bien, la clasificación de fotos por rostros o caras que llevan a cabo los teléfonos inteligentes.
Ventajas y desventajas de las redes neuronales convolucionales en la inteligencia artificial
Entre las principales ventajas de las redes neuronales convolucionales en la inteligencia artificial encontramos:
- Son sumamente eficaces para la identificación de patrones de tipo visual.
- Su alta capacidad para poder procesar grandes cantidades de datos visuales.
- La gran posibilidad para aprender y mejorar con el tiempo
Entre sus principales desventajas podemos mencionar:
- Puede necesitar una gran cantidad de datos para poder operar.
- Necesita mucho tiempo para el entrenamiento y para su optimización correcta.
Conclusiones
En conclusión, se puede decir que las redes neuronales convolucionales son muy importantes porque su aplicación ha permitido grandes avances. Especialmente en el campo de la visión por computadoras y reconocimiento de imágenes.
Adicionalmente, su proceso es muy simple. Empieza con la entrada de una imagen, luego viene la extracción de características. Posteriormente, se comprime con las características esenciales, para poder hacer la clasificación final basada en las características extraídas.
Autores
Publicado por Myriam Quiroa el 6 junio 2023.
Revisado por última vez el 10 junio 2023.
Cómo citar este artículo
Quiroa, M. (2023). Red neuronal convolucional. Economipedia. https://economipedia.com/definiciones/red-neuronal-convolucional.html
Sobre Economipedia
Este artículo forma parte de la enciclopedia de Economipedia, una plataforma de educación financiera que ayuda a millones de personas a entender la economía, aprender a invertir y mejorar sus finanzas personales. Fundada en 2012 por Andrés Sevilla Arias y desarrollada por más de 50 economistas y asesores financieros.
Todavía no hay comentarios
Hay 2 tipos de personas: las que leen y se van…y las que dejan huella 👇




