Prueba de Kolmogorov – Smirnoff (K-S)
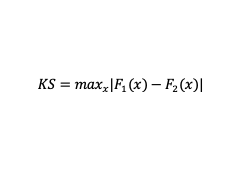
La prueba de Kolmogorov–Smirnoff (K-S) es un contraste no paramétrico que tiene como objetivo determinar si la frecuencia de dos conjuntos de datos distintos siguen la misma distribución alrededor de su media.
En otras palabras, la prueba Kolmogorov–Smirnoff (K-S) es un test que se adapta a la forma de los datos y se utiliza para comprobar si dos muestras distintas siguen la misma distribución.
¿Por qué es un contraste no paramétrico?
La gracia de la característica “no paramétrica” es que se adapta a los datos y, en consecuencia, a las distribuciones que puedan seguir la frecuencia de los datos. Además, esta característica nos ahorra tener que suponer a priori qué distribución sigue la muestra.
Importancia de la prueba K-S
¿Cuántas veces nos han dado dos muestras y hemos calculado el coeficiente de correlación de Pearson sin pensarlo dos veces? En otras palabras, si queremos ver la relación lineal entre dos conjuntos de datos, sería lícito calcular la correlación, ¿no?
Esta deducción sería cierta si las distribuciones de las dos muestras siguen una distribución normal. El coeficiente de correlación asume que las distribuciones son normales, si nos saltamos esta asunción, el resultado del coeficiente de correlación es erróneo. Para los contrastes de hipótesis y los intervalos de confianza también asumimos que la población se distribuye mediante una distribución normal.
Al igual que todos los contrastes de hipótesis que involucran estadísticos, es importante contar con un gran volumen de datos para tener resultados estadísticamente significativos. Es posible que rechacemos por error una hipótesis nula debido a que la muestra es pequeña. Además, también es importante que esta muestra tenga algunos casos extremos (outliers, en inglés) para dar consistencia al resultado del test.
Procedimiento del test
El procedimiento de los siguientes pasos.
Hipótesis
El primer paso será comprobar si ambas muestras tienen la misma distribución. Para ello realizamos un contraste de hipótesis suponiendo que ambas muestras tienen la misma distribución contra la hipótesis alternativa de que son distintas.

Estadístico
Trabajamos con las funciones de distribución acumuladas de dos muestras, F1(x) y F2(x):
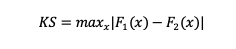
¡Que no cunda el pánico! Analizamos la fórmula anterior con calma:
- La parte importante de la fórmula es el signo de diferencia (-). Estamos buscando diferencias verticales en las distribuciones. Entonces, restaremos ambas funciones de distribución acumulada.
- El operador “max”. Nos interesa encontrar la diferencia mayor o máxima para ver cómo de diferentes pueden llegar a ser ambas distribuciones.
- El valor absoluto. Empleamos el valor absoluto para que el orden de los operadores no altere el resultado. En otras palabras, no importa qué F(x) tenga el signo negativo:
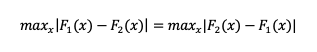
Valor crítico
Para muestras grandes existe la aproximación al valor crítico para K-S que depende del nivel de significación (%):
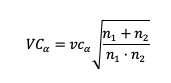
Donde n1 y n2 son el tamaño de la muestra para la muestra de F1(x) y F2(x) respectivamente.
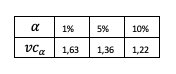
Algunos valores críticos calculados:
Regla de rechazo

Aplicación
Muy a menudo queremos probar si dos distribuciones son lo suficientemente diferentes ente ellas cuando queremos construir escenarios de predicción (trabajamos con dos muestras) o cuando queremos evaluar qué distribución se adapta mejor a los datos (trabajamos con una sola muestra).
Autores
Publicado por Paula Rodó el 5 febrero 2020.
Revisado por última vez el 24 noviembre 2022.
Cómo citar este artículo
Rodó, P. (2020). Prueba de Kolmogorov – Smirnoff (K-S). Economipedia. https://economipedia.com/definiciones/prueba-de-kolmogorov-smirnoff-k-s.html
Sobre Economipedia
Este artículo forma parte de la enciclopedia de Economipedia, una plataforma de educación financiera que ayuda a millones de personas a entender la economía, aprender a invertir y mejorar sus finanzas personales. Fundada en 2012 por Andrés Sevilla Arias y desarrollada por más de 50 economistas y asesores financieros.
Todavía no hay comentarios
Hay 2 tipos de personas: las que leen y se van…y las que dejan huella 👇




